
主要な研究開発プロジェクト
NEDO「高効率・高速処理を可能とする AIチップ・次世代コンピューティングの技術開発」(HP)
研究開発項目〔2〕-(2)新原理コンピューティング技術の開発(脳型等データ処理高度化関連技術)(研究開発項目② 次世代コンピューティング技術の開発)
「ニューロモルフィックダイナミクスに基づく超低電力エッジAIチップの研究開発とその応用展開」 (内部コードネーム:NEDO2b)
(研究開発責任者:森江 隆)(2022.4-2025.3ー(2028.3))
「電圧駆動不揮発性メモリを用いた超省電力ブレインモルフィックシステムの研究開発」 (内部コードネーム:NEDO3)
(九工大責任者:森江 隆)(2020.8-2023.3-2025.3延長)
【終了】「未来共生社会にむけたニューロモルフィックダイナミクスのポテンシャルの解明 」 (ホームページ)(内部コードネーム:NEDO2a)
(研究開発責任者:浅田 稔)(九工大責任者:森江 隆)(2018.10-2023.3)
【終了プロジェクト】
NEDO「次世代人工知能・ロボット中核技術開発」(紹介ハンドブック2019年度版)
研究開発項目(1) 大規模目的基礎研究・先端技術研究開発
「時間領域脳型人工知能システムの基盤技術開発」(内部コードネーム:NEDO1)
(研究責任者:森江 隆)(2017.9-2019.1)
家庭用サービスロボット(ロボカップ@ホーム関連)活動(HP)
カーロボAI連携大学院関連ページ
主要な研究項目
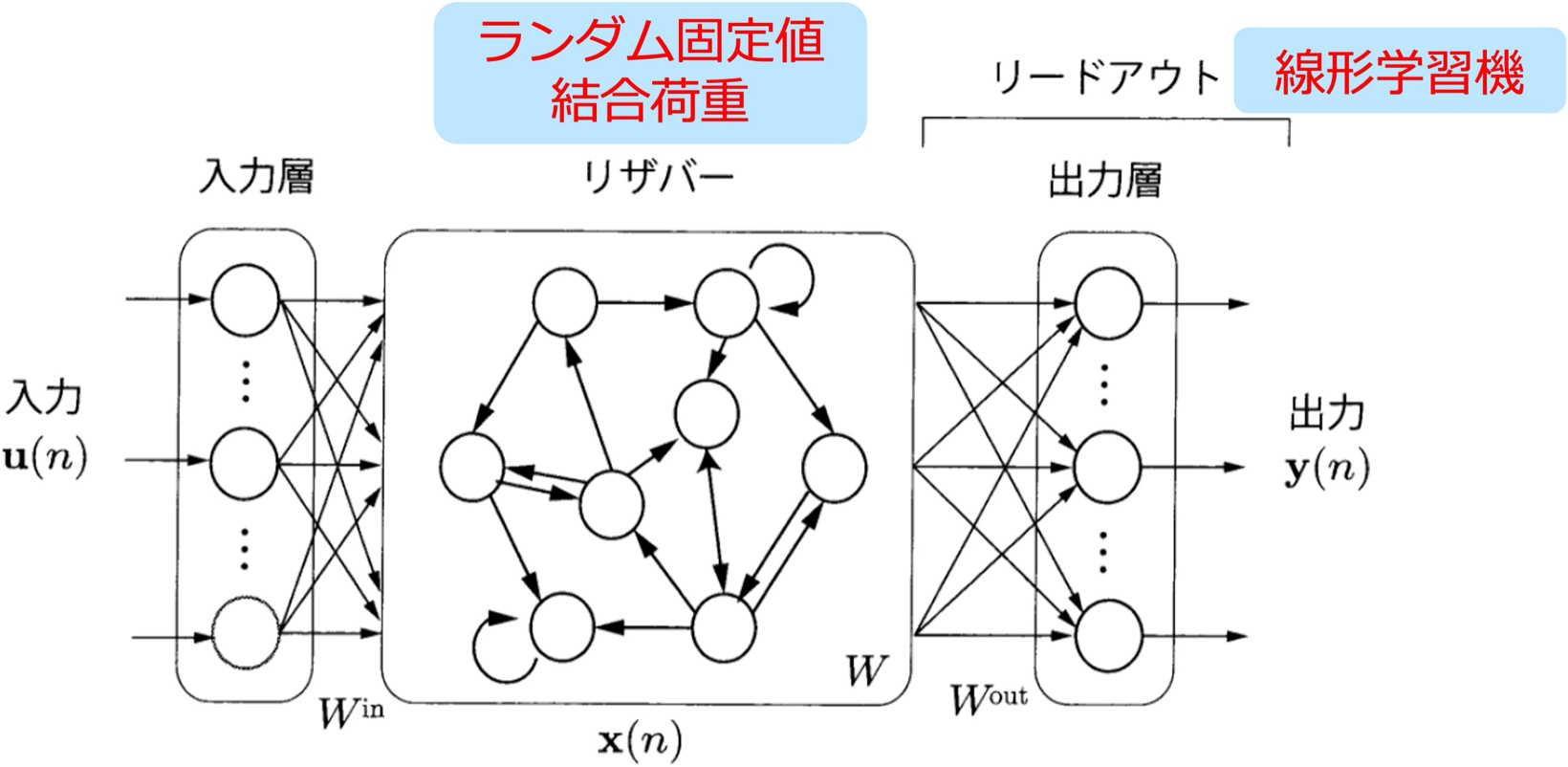
リザバー計算モデル
リザバー計算モデル(Researvoir Computing,レザバーとも言う)は,自己回帰型ニューラルネットワーク Recurrent Neural Network(RNN)の一種で,入力層・リザバー層・出力(リードアウト)層の3層からなるモデルです.リザバー層はランダムな固定値荷重によるリカレント構造を持つネットワークです.このモデルは特に,時系列情報処理に対して威力を発揮します.通常の深層学習ネットワークが全ての層の荷重をバックプロパゲーション学習法で最適化していくのに対し,リザバー計算モデルでは,リザバーに内在する多様で複雑なダイナミクスから,問題を解くために必要な要素のみを抜き出して組み合わせる(リードアウト層のみを学習する)ことが特徴です.このため,少ない学習データでも学習ができ,簡便・軽量・高速な学習が可能です.本プロジェクト(NEDO2a/2b)での中心的な役割を果たしているAIモデルです.また,脳型モデル研究(NEDO1/3)との関連で言えば,リザバーは皮質のモデルとも考えられており,前頭前野モデルとしても採用されています.
固定のランダム結合の単層リカレントネットワークであるリザバーが,深層ネットワークと同程度の能力を有することはにわかに信じがたいかもしれません.高性能なリザバー計算を実現するにはレザバー内部状態の時間発展(ダイナミクス)をいかに制御するかという,カオスを含めた非線形力学系(非線形物理学)の知見が重要です(これは深層学習を扱うアルゴリズム主体の情報系技術者にはなじみが薄く,それがリザバー計算モデル普及の妨げになっているように感じられます).具体的にはリザバーの性能は,リザバーにどれだけ強い非線形性と長期の時間記憶を内在させられるかによって決まります.非線形性が弱いと高い性能が出せませんし,強すぎるとレザバー全体がカオス状態となり,所望の適切な入出力関係が実現できません.できるだけ高性能なリザバーとするには,カオスになるかならないかという(「カオスの縁」Edge of chaos)状態に設定することが重要と言われています.
代表的モデルとして広く適用が試みられているのが,通常の線形積和演算とシグモイド関数などの非線形変換で構成されるエコーステートネットワーク(Echo State Network: ESN)です.一方で,非線形性に制約はないため,様々な非線形変換モデルを適用することができます.これを様々な物理系で実現する「物理リザバー」が,物理系で情報処理を行わせようとするデバイス・材料系研究者の間で盛んに研究されています.
計算機アーキテクチャ・集積回路実装の観点からは,リザバー内の結合については下記TACT方式のようなインメモリ計算(Computing in-memory; CiM)手法が適用でき,さらに,深層ネットワークで回路レイアウト面積・消費電力のオーバーヘッドとなるとなる層間一時記憶がリザバー計算機では不要なため,超高効率(超低消費エネルギー動作)AIハードウェアが実現可能です.アナログ的な非線形性を実現するには,アナログ回路技術によるハードウェア実現が適しているため,本研究グループではディジタル集積回路実装だけでなく,アナログメモリ素子を用いたリザバー計算用アナログ集積回路の開発を行っています.
ちなみに,リザバーと同じように固定ランダム結合を有していますが,リカレント結合ではなく入力から出力へのフィードフォワード結合のみのネットワークからなるモデルは,エクストリーム学習器(Extreme Learning Machine)と呼ばれます.また,誤差逆伝搬学習の逆伝搬部分の荷重をランダムにして,層毎ではなく一気に全層で学習を進める学習法としてダイレクトフィードバックアラインメント(Direct Feedback Alighnment)法という手法が知られています.このように固定ランダム荷重を用いる手法は新規デバイスや材料系で実現しやすく,注目されています.
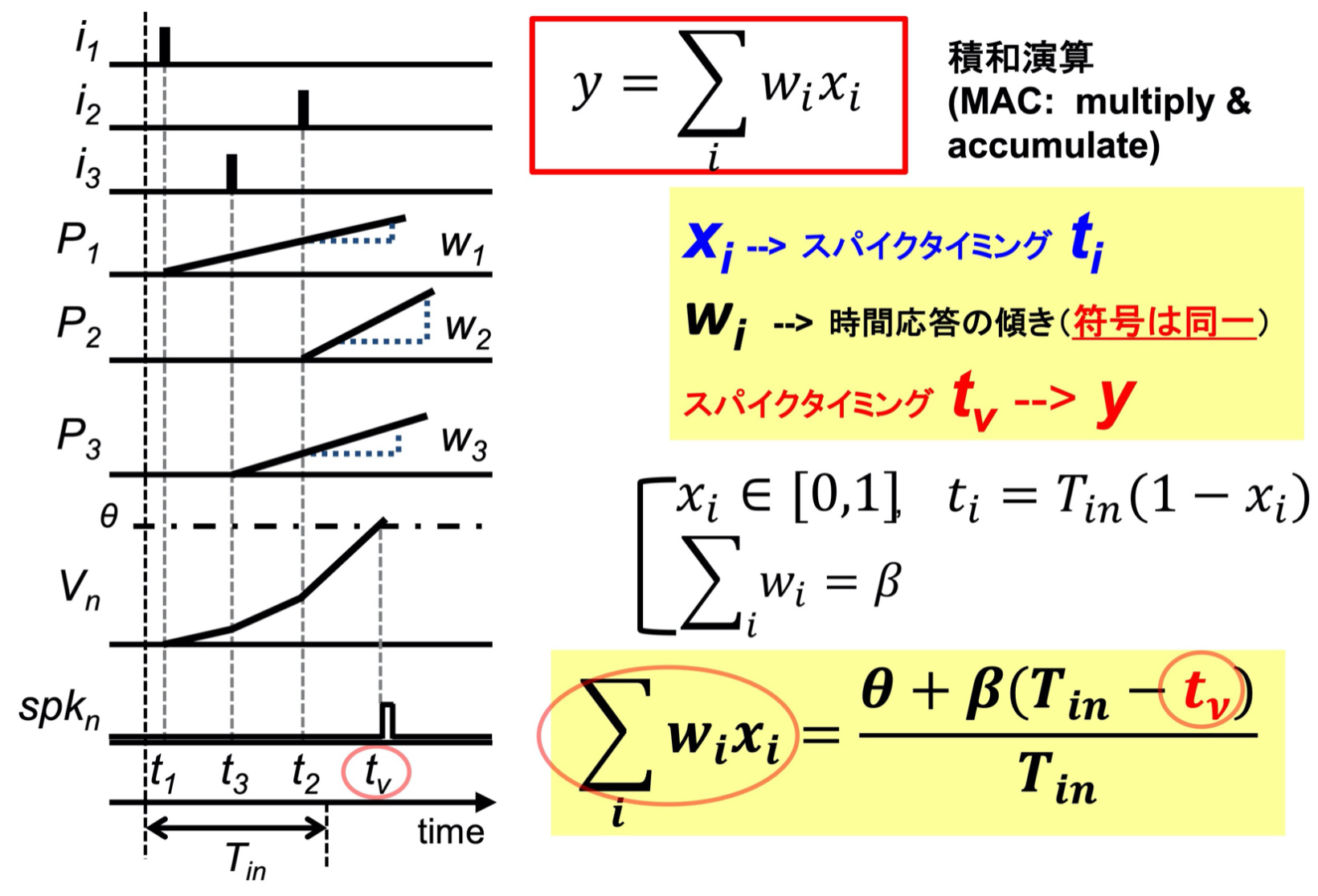
過渡特性を利用した時間領域アナログ演算方式(TACT方式)
我々がTACT(Time-domain Analog Computing with Transient states)と名付けた計算モデルと集積回路方式は,最も簡単なスパイキングニューロンモデルである積分発火型ニューロンモデルにヒントを得て,究極の低消費エネルギーで積和演算を行うことができる,時間領域アナログ集積回路方式です.これは近年,専用AIチップの先端研究で主流になっているインメモリ計算(CiM)方式での究極的な高効率方式と考えています.
この方式では情報は時間タイミングで表現され,早く(遅く)入力されたスパイクが大きな(小さな)値を表現します.入力タイミングからシナプス荷重に比例する傾きでニューロン内部状態寄与分が増加(または減少)し,全入力からの寄与の総和が内部状態となります.これが所定のしきい値を超えたタイミングでスパイクが出力されます.この出力タイミングは入力と荷重の積和演算結果を表現します.
TACT方式は,単一のキャパシタCに並列に接続された複数の抵抗Riの電子回路で実現できます.これらの抵抗には入力スパイクタイミングで立ち上がるステップ電圧Viniが与えられ,キャパシタの充電電圧Vがニューロン内部状態を表現します.この積和演算を実行するときに消費されるエネルギーは最大でもCV2となります.集積回路で実装したときにCをできるだけ小さくし(例えば,入力当たり1fF),Vを1Vとすると,1積和(2演算)を1fJで実現することができ,2,000TOPS/Wの演算効率が実現できます.これは,演算精度を考慮すると最先端ディジタルAIチップよりも100倍以上の低消費エネルギー演算です.一方で,時間領域で情報を表現するためには,所定の時間分解能を確保する必要があり,時定数として1〜100μsが必要です.これはR=1G〜100GΩに相当し,極めて高抵抗なアナログメモリ素子を用意する必要があり,難易度が高い製造技術が必要になります.
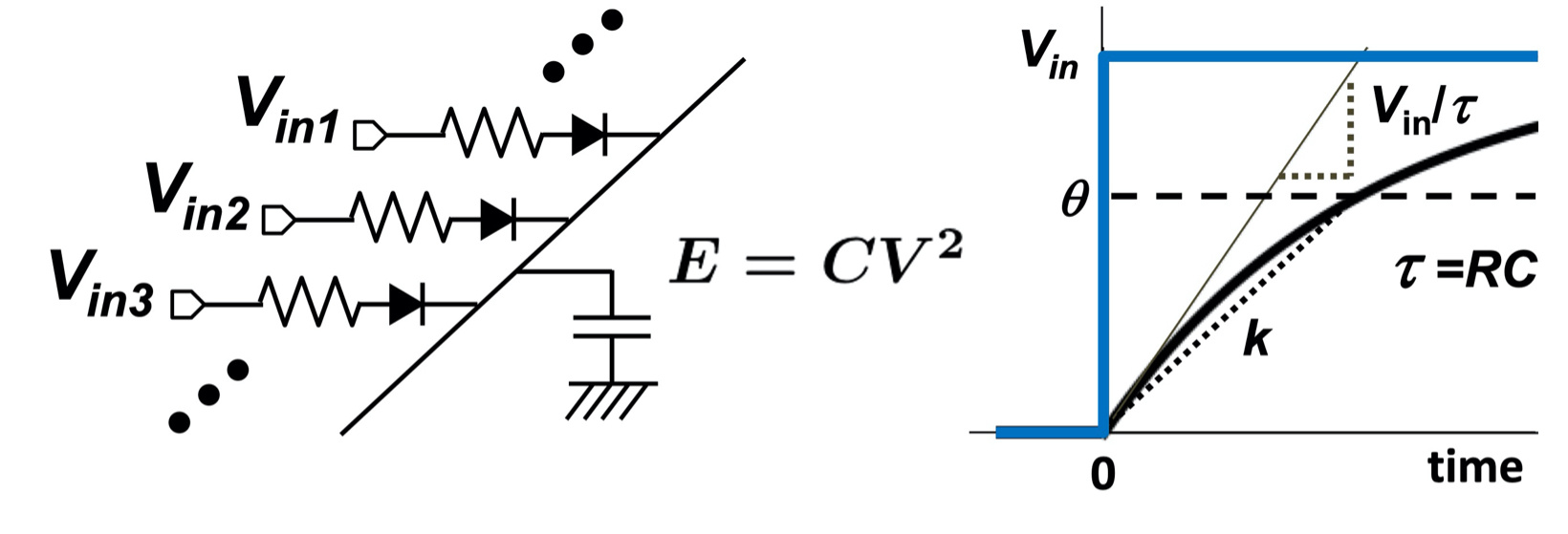
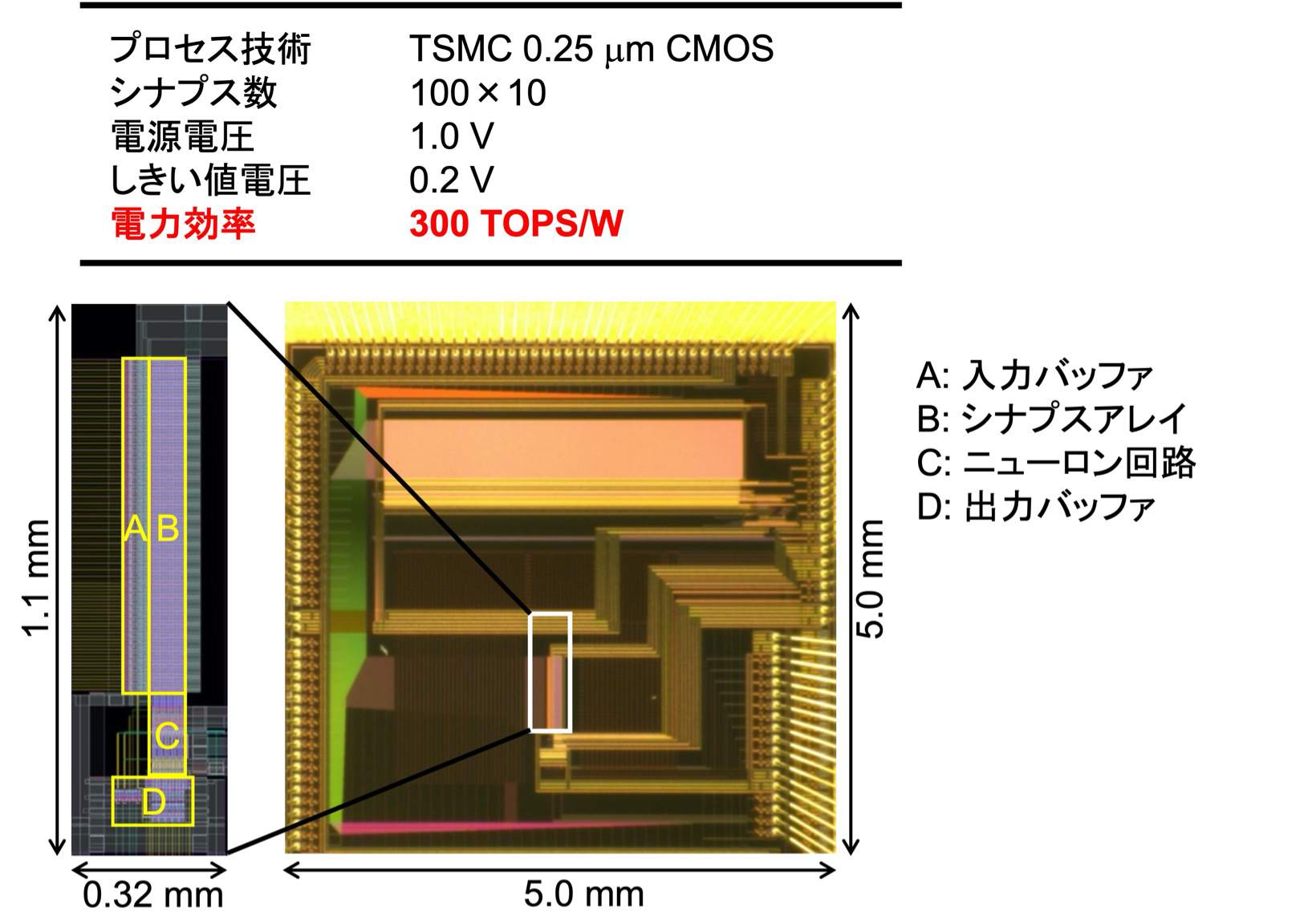
TACT方式により,0.25μmCMOS技術を用いて積和演算回路を設計・試作しました[文献].シナプス荷重はSRAMセルを用い,シナプス抵抗はMOSFETのサブスレショルド領域動作により1GΩ以上を実現しました.この回路は300TOPS/Wの演算効率を達成しましたが,より微細な製造技術を用いることでさらに演算効率を向上させることが可能です.本プロジェクト(NEDO2b)では,SONOS型アナログフラッシュメモリ素子でシナプス荷重を実現するAIチップを開発しています.
カオスボルツマンマシンとそのリザバー応用
カオスボルツマンマシン(Chaotic Boltzmann Machine: CBM)は,よく知られた古典的ニューラルネットワークモデルであるボルツマンマシンの,確率的動作をカオス動作で置き換えたモデルです.ニューロンユニット内の指数関数演算により非線形性を実現し,3ニューロン以上のネットワークでカオスを生じることが知られています.本プロジェクト(NEDO2a)ではディジタル回路(FPGA)での実装を行っており[文献],アナログ集積回路チップも開発済みです[文献].
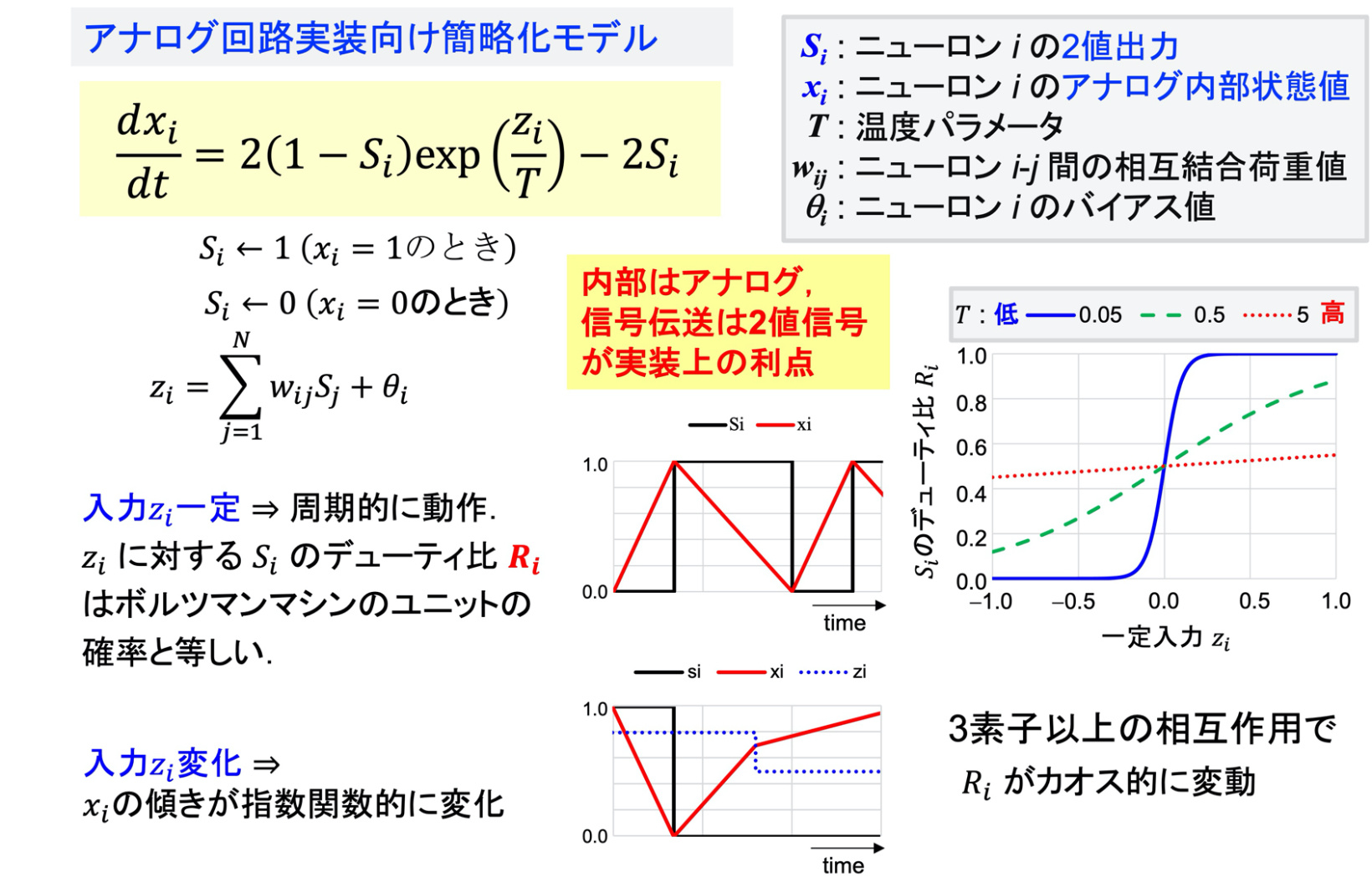
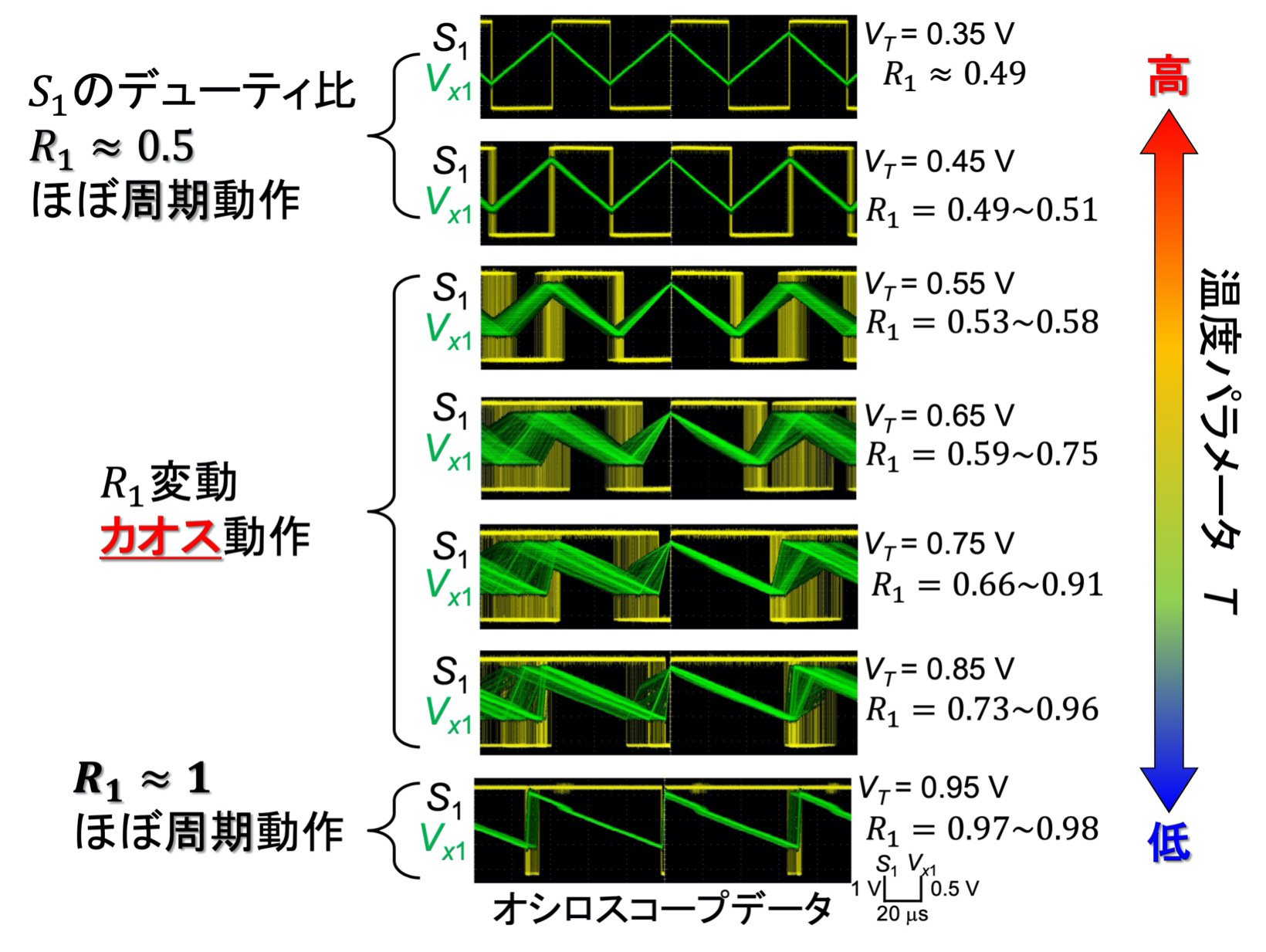
本プロジェクト(NEDO2b)では,CBMをユニットとするリザバー計算モデルをディジタルおよびアナログ方式(TACT)で集積回路実装しました[文献].さらに,シナプス荷重を下記のアナログメモリ素子で実装したアナログ集積回路も開発中です.
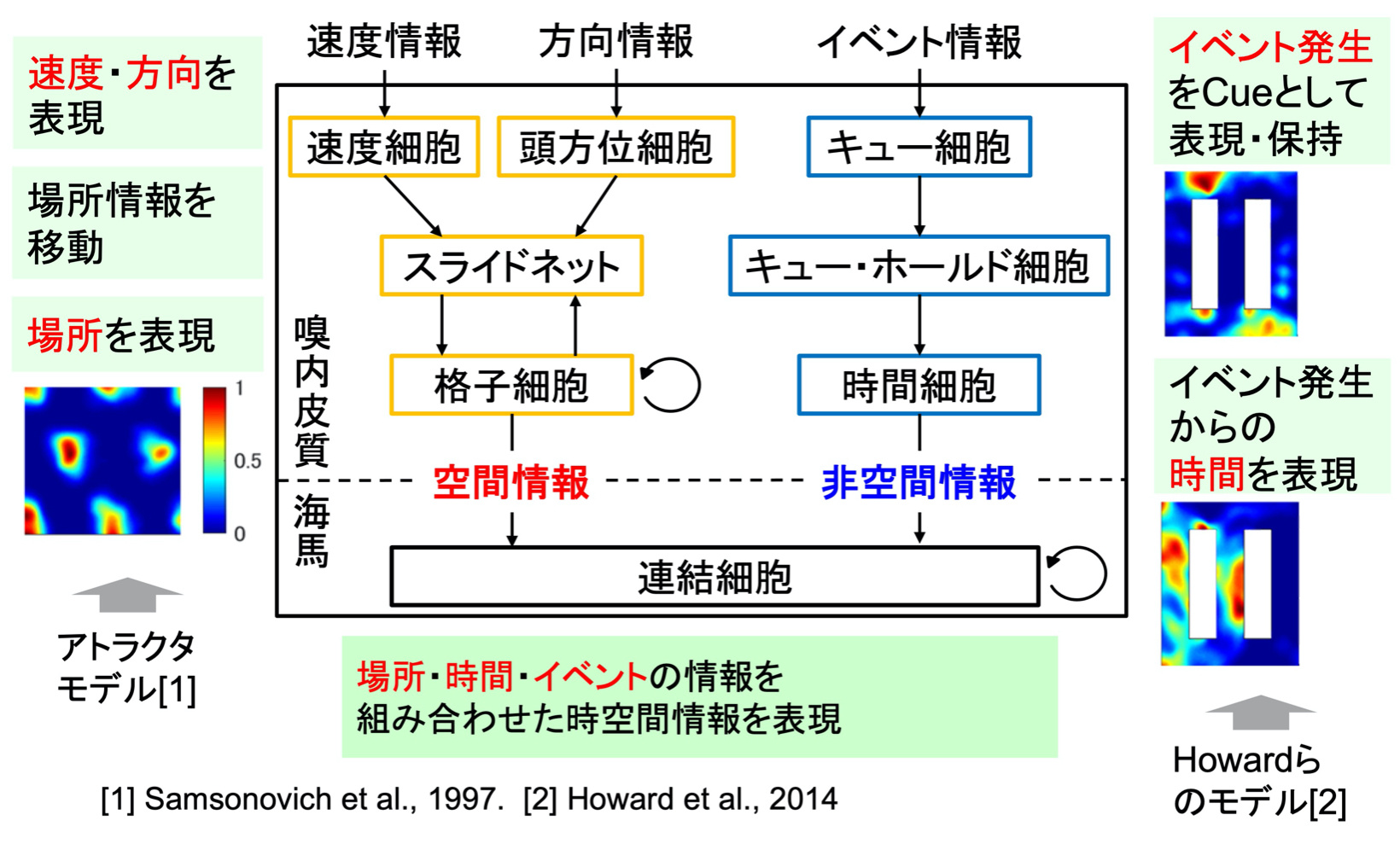
海馬・嗅内皮質の機能にヒントを得た脳型記憶モデル
現在普及が進んでいる深層学習ベースのAIでは,大量のデータを用いて大規模な深層ネットワークで学習することで,人間が共通に持つ知識や機能(一般的な画像認識機能)を実現します.一方,人は個々人が異なる経験を経ることで,人間らしい知能を身につけていきます.このような個人に特有の知識・経験をAIに付与するためには,深層学習とは別のタイプのAIモデルが必要です.本プロジェクトでは,脳の一部位である海馬とその周辺(嗅内皮質)の機能に注目し,それらの工学的モデルを構築して,超効率なハードウェアで実装することを目指しています.クラウドベースのAIではなく,エッジAIハードウェアで構成することで,通信環境に依存せず,スタンドアロンで動作し,人のプライバシーにも配慮したAIシステムを構築することができます.
海馬の機能として重要な点は,場所とイベントを結合して記憶する「エピソード記憶」です.本プロジェクト(NEDO3)では,ラットなどを用いた生理学ベースの海馬-嗅内皮質ネットワークモデルを構築しました.さらに,長期記憶と組み合わせた工学的モデルも提案しました[文献].
アナログメモリ素子
TACT方式を用いて超低電力なAIチップを構築するには,アナログメモリ素子が必要です.過去数10年にわたるニューラルネットワークハードウェア研究の歴史において,実用的なアナログメモリ素子が作製できないことが最大のネックでした.近年,抵抗変化型メモリ(ReRAM)などの様々な新規メモリ素子の研究開発が活発化することで,アナログメモリ素子の実用化にも目処が立ってきました.本プロジェクト(NEDO2a/2b)では,(株)フローディアが開発しているSONOS型フラッシュメモリ素子をアナログメモリとして用いて,超低電力AIチップを開発しています.




